
说实话,在当下的体育数据圈,大家都在玩一场关于“毫秒”的生存赛跑。尤其是在滚球这种瞬息万变的赛中场景下,你看到的每一个比分跳动、每一次赔率切换,背后其实都是一场跨越数千公里的数据接力。
在华体会的技术架构演进中,边缘计算(Edge Computing)正从幕后走向台前。它不是什么玄学,简单说,就是为了干掉那该死的延迟波动,让数据跑得更稳。
滚球数据波动问题的技术本质
高频数据更新导致系统压力
滚球场景简直就是数据的“轰炸区”。一场高水平足球赛,从比分、红黄牌到控球率,每一秒钟都有大量状态信息需要更新并推送到百万级用户的终端上。这种更新频率是以毫秒计量的,任何细微的滞后,都会让你看到的界面信息变成“历史文物”。
网络延迟造成显示不一致
延迟越高,你和赛场真实情况之间的“代差”就越大。想象一下,赛场上已经判了点球,但你的APP还停留在中场带球。这种延迟叠加不仅打乱节奏,更会让不同地区的用户看到完全不同步的结果。在华体会看来,这种由于链路过长导致的不对称,是必须被消灭的体验杀手。
当几十万人同时刷新页面,集中式架构的中心服务器压力会瞬间爆表,这是延迟波动的罪魁祸首。
什么是边缘计算?核心工作逻辑
计算节点下沉到网络边缘
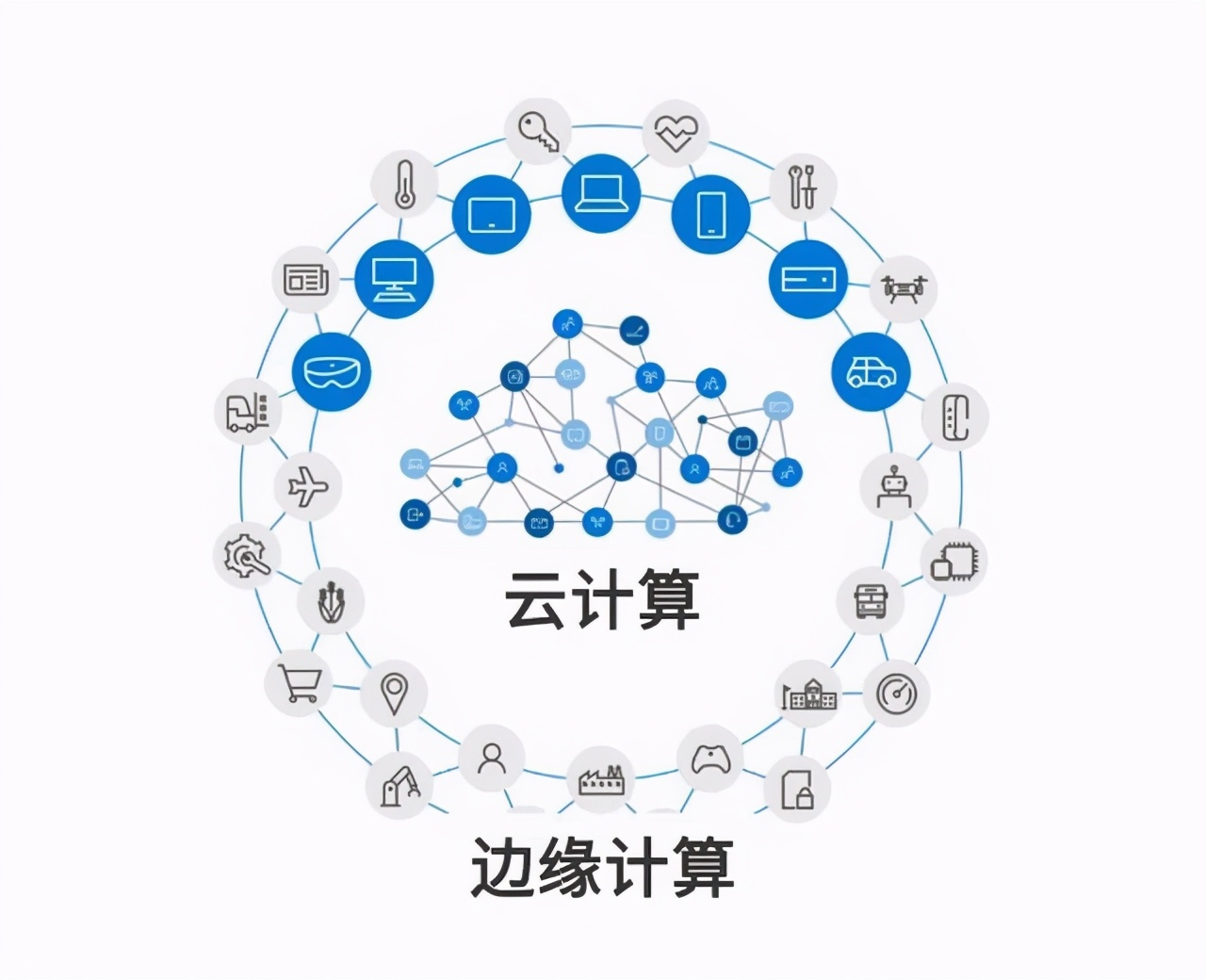
传统的“云计算”模式像是一家超大型超市,不管你在哪,都得跑去总部提货。而边缘计算则是直接在离你最近的街道开了无数个便利店。华体会通过在不同区域部署分布式节点,让原本需要跨海越洋的数据传输,缩短到了区区几百公里的物理距离。
这种架构最爽的一点在于,它大幅减少了对中心服务器的依赖。大部分的逻辑运算和初步数据分发直接在边缘侧就搞定了,总部只需要处理核心指令。
关于“跳水问题”的真实技术解释
数据突变的形成原因
很多玩家常说的“数据跳水”或显示突变,其实在技术层面大多源于延迟的叠加。当多层网络跳转导致同步不一致时,系统为了追上真实进度,会强行进行数据覆盖。
这就好比看电影卡顿后突然快进。这种突变往往是由多节点更新速度不一,或者各个节点的缓存机制刷新策略存在微小差异导致的。在华体会的数据治理中,这属于典型的分布式系统一致性挑战,而非单一的服务器故障。
华体会系统中的边缘计算架构
华体会在这一块的投入,主要集中在几个“看不见”的地方。
通过多区域节点部署,系统能确保你无论在哪个角落,都能接入逻辑距离最短的服务器。配合动态负载分配机制,流量会自动流向资源更充裕的节点。这就避免了某一场热门赛事(比如欧冠决赛)突然引爆流量时,单一节点被“挤爆”导致的数据卡顿。
常见误区解析
虽然技术很猛,但咱们得理清一些常识。
延迟无法被彻底消除: 只要有物理距离,延迟就存在。边缘计算是把延迟从“肉眼可见”优化到“无法察觉”。
用户本地网络依然关键: 如果你身处的WiFi信号微弱,或者手机正在下载几个G的更新包,那再牛的边缘节点也救不了你的卡顿。
数据同步的复杂性: 节点越多,保持数据绝对同步的难度就越大。这是一个持续博弈的过程。
边缘计算不再是可选的插件,它是支撑华体会这类平台实时数据稳如老狗的底层基石。通过把计算能力下沉、优化传输路径,确实显著改善了那种由于延迟叠加导致的“跳水”现象。
但要明白,延迟优化是个系统工程。边缘计算是其中最硬核的那块拼图,但它还需要配合更高标准的数据协议和本地网络环境。说到底,技术是为了让数据更透明、更即时,而理解这些底层逻辑,能让你在面对数据波动时多一份理性和从容。